1# Contributors
2
3The project differentiates between 3 levels of contributors:
4
5- Contributors: people who have contributed before (no special privileges)
6- Collaborators (Triage): people with significant contributions, who may be responsible for some parts of the code, and are expected to maintain and review contributions for the code they own
7- Maintainers: responsible for reviewing and merging PRs, after approval from the code owners
8
9# AI Usage Policy
10
11> [!IMPORTANT]
12> This project does **not** accept pull requests that are fully or predominantly AI-generated. AI tools may be utilized solely in an assistive capacity.
13>
14> Detailed information regarding permissible and restricted uses of AI can be found in the [AGENTS.md](AGENTS.md) file.
15
16Code that is initially generated by AI and subsequently edited will still be considered AI-generated. AI assistance is permissible only when the majority of the code is authored by a human contributor, with AI employed exclusively for corrections or to expand on verbose modifications that the contributor has already conceptualized (e.g., generating repeated lines with minor variations).
17
18If AI is used to generate any portion of the code, contributors must adhere to the following requirements:
19
201. Explicitly disclose the manner in which AI was employed.
212. Perform a comprehensive manual review prior to submitting the pull request.
223. Be prepared to explain every line of code they submitted when asked about it by a maintainer.
234. It is strictly prohibited to use AI to write your posts for you (bug reports, feature requests, pull request descriptions, Github discussions, responding to humans, ...).
24
25For more info, please refer to the [AGENTS.md](AGENTS.md) file.
26
27# Pull requests (for contributors & collaborators)
28
29Before submitting your PR:
30- Search for existing PRs to prevent duplicating efforts
31- llama.cpp uses the ggml tensor library for model evaluation. If you are unfamiliar with ggml, consider taking a look at the [examples in the ggml repository](https://github.com/ggml-org/ggml/tree/master/examples/). [simple](https://github.com/ggml-org/ggml/tree/master/examples/simple) shows the bare minimum for using ggml. [gpt-2](https://github.com/ggml-org/ggml/tree/master/examples/gpt-2) has minimal implementations for language model inference using GPT-2. [mnist](https://github.com/ggml-org/ggml/tree/master/examples/mnist) demonstrates how to train and evaluate a simple image classifier
32- Test your changes:
33 - Execute [the full CI locally on your machine](ci/README.md) before publishing
34 - Verify that the perplexity and the performance are not affected negatively by your changes (use `llama-perplexity` and `llama-bench`)
35 - If you modified the `ggml` source, run the `test-backend-ops` tool to check whether different backend implementations of the `ggml` operators produce consistent results (this requires access to at least two different `ggml` backends)
36 - If you modified a `ggml` operator or added a new one, add the corresponding test cases to `test-backend-ops`
37- Create separate PRs for each feature or fix:
38 - Avoid combining unrelated changes in a single PR
39 - For intricate features, consider opening a feature request first to discuss and align expectations
40 - When adding support for a new model or feature, focus on **CPU support only** in the initial PR unless you have a good reason not to. Add support for other backends like CUDA in follow-up PRs
41- Consider allowing write access to your branch for faster reviews, as reviewers can push commits directly
42
43After submitting your PR:
44- Expect requests for modifications to ensure the code meets llama.cpp's standards for quality and long-term maintainability
45- Maintainers will rely on your insights and approval when making a final decision to approve and merge a PR
46- If your PR becomes stale, rebase it on top of latest `master` to get maintainers attention
47- Consider adding yourself to [CODEOWNERS](CODEOWNERS) to indicate your availability for fixing related issues and reviewing related PRs
48
49# Pull requests (for maintainers)
50
51- Squash-merge PRs
52- Use the following format for the squashed commit title: `<module> : <commit title> (#<issue_number>)`. For example: `utils : fix typo in utils.py (#1234)`
53- Optionally pick a `<module>` from here: https://github.com/ggml-org/llama.cpp/wiki/Modules
54- Let other maintainers merge their own PRs
55- When merging a PR, make sure you have a good understanding of the changes
56- Be mindful of maintenance: most of the work going into a feature happens after the PR is merged. If the PR author is not committed to contribute long-term, someone else needs to take responsibility (you)
57
58Maintainers reserve the right to decline review or close pull requests for any reason, particularly under any of the following conditions:
59- The proposed change is already mentioned in the roadmap or an existing issue, and it has been assigned to someone.
60- The pull request duplicates an existing one.
61- The contributor fails to adhere to this contributing guide.
62
63# Coding guidelines
64
65- Avoid adding third-party dependencies, extra files, extra headers, etc.
66- Always consider cross-compatibility with other operating systems and architectures
67- Avoid fancy-looking modern STL constructs, use basic `for` loops, avoid templates, keep it simple
68- Vertical alignment makes things more readable and easier to batch edit
69- Clean-up any trailing whitespaces, use 4 spaces for indentation, brackets on the same line, `void * ptr`, `int & a`
70- Use sized integer types such as `int32_t` in the public API, e.g. `size_t` may also be appropriate for allocation sizes or byte offsets
71- Declare structs with `struct foo {}` instead of `typedef struct foo {} foo`
72 - In C++ code omit optional `struct` and `enum` keyword whenever they are not necessary
73 ```cpp
74 // OK
75 llama_context * ctx;
76 const llama_rope_type rope_type;
77
78 // not OK
79 struct llama_context * ctx;
80 const enum llama_rope_type rope_type;
81 ```
82
83 _(NOTE: this guideline is yet to be applied to the `llama.cpp` codebase. New code should follow this guideline.)_
84
85- Try to follow the existing patterns in the code (indentation, spaces, etc.). In case of doubt use `clang-format` (from clang-tools v15+) to format the added code
86- For anything not covered in the current guidelines, refer to the [C++ Core Guidelines](https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines)
87- Tensors store data in row-major order. We refer to dimension 0 as columns, 1 as rows, 2 as matrices
88- Matrix multiplication is unconventional: [`C = ggml_mul_mat(ctx, A, B)`](https://github.com/ggml-org/llama.cpp/blob/880e352277fc017df4d5794f0c21c44e1eae2b84/ggml.h#L1058-L1064) means $C^T = A B^T \Leftrightarrow C = B A^T.$
89
90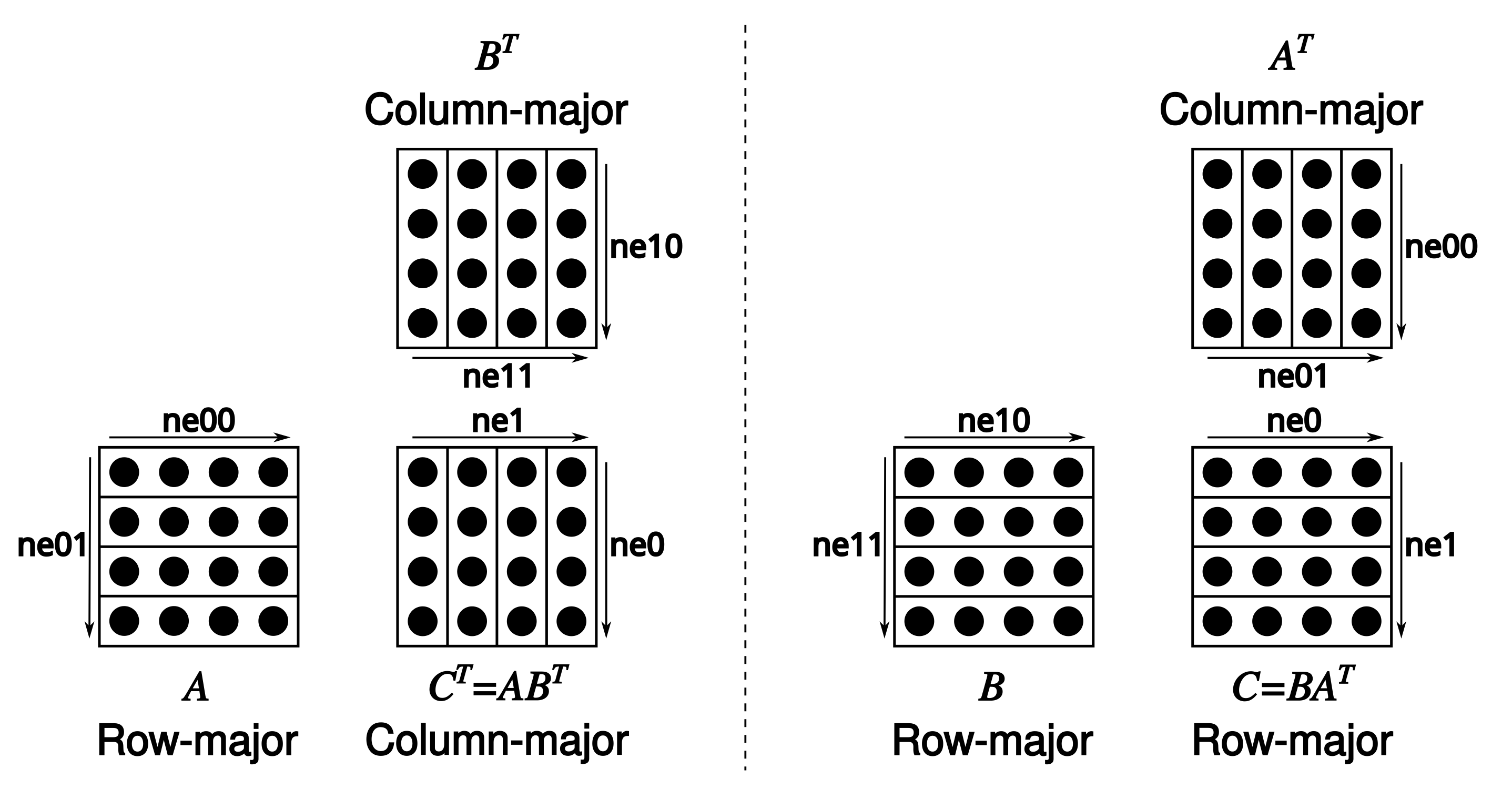
91
92# Naming guidelines
93
94- Use `snake_case` for function, variable and type names
95- Naming usually optimizes for longest common prefix (see https://github.com/ggml-org/ggml/pull/302#discussion_r1243240963)
96
97 ```cpp
98 // not OK
99 int small_number;
100 int big_number;
101
102 // OK
103 int number_small;
104 int number_big;
105 ```
106
107- Enum values are always in upper case and prefixed with the enum name
108
109 ```cpp
110 enum llama_vocab_type {
111 LLAMA_VOCAB_TYPE_NONE = 0,
112 LLAMA_VOCAB_TYPE_SPM = 1,
113 LLAMA_VOCAB_TYPE_BPE = 2,
114 LLAMA_VOCAB_TYPE_WPM = 3,
115 LLAMA_VOCAB_TYPE_UGM = 4,
116 LLAMA_VOCAB_TYPE_RWKV = 5,
117 };
118 ```
119
120- The general naming pattern is `<class>_<method>`, with `<method>` being `<action>_<noun>`
121
122 ```cpp
123 llama_model_init(); // class: "llama_model", method: "init"
124 llama_sampler_chain_remove(); // class: "llama_sampler_chain", method: "remove"
125 llama_sampler_get_seed(); // class: "llama_sampler", method: "get_seed"
126 llama_set_embeddings(); // class: "llama_context", method: "set_embeddings"
127 llama_n_threads(); // class: "llama_context", method: "n_threads"
128 llama_adapter_lora_free(); // class: "llama_adapter_lora", method: "free"
129 ```
130
131 - The `get` `<action>` can be omitted
132 - The `<noun>` can be omitted if not necessary
133 - The `_context` suffix of the `<class>` is optional. Use it to disambiguate symbols when needed
134 - Use `init`/`free` for constructor/destructor `<action>`
135
136- Use the `_t` suffix when a type is supposed to be opaque to the user - it's not relevant to them if it is a struct or anything else
137
138 ```cpp
139 typedef struct llama_context * llama_context_t;
140
141 enum llama_pooling_type llama_pooling_type(const llama_context_t ctx);
142 ```
143
144 _(NOTE: this guideline is yet to be applied to the `llama.cpp` codebase. New code should follow this guideline)_
145
146- C/C++ filenames are all lowercase with dashes. Headers use the `.h` extension. Source files use the `.c` or `.cpp` extension
147- Python filenames are all lowercase with underscores
148
149- _(TODO: abbreviations usage)_
150
151# Preprocessor directives
152
153- _(TODO: add guidelines with examples and apply them to the codebase)_
154
155 ```cpp
156 #ifdef FOO
157 #endif // FOO
158 ```
159
160# Code maintenance
161
162- Existing code should have designated collaborators and/or maintainers specified in the [CODEOWNERS](CODEOWNERS) file reponsible for:
163 - Reviewing and merging related PRs
164 - Fixing related bugs
165 - Providing developer guidance/support
166
167- When adding or modifying a large piece of code:
168 - If you are a collaborator, make sure to add yourself to [CODEOWNERS](CODEOWNERS) to indicate your availability for reviewing related PRs
169 - If you are a contributor, find an existing collaborator who is willing to review and maintain your code long-term
170 - Provide the necessary CI workflow (and hardware) to test your changes (see [ci/README.md](https://github.com/ggml-org/llama.cpp/tree/master/ci))
171
172- New code should follow the guidelines (coding, naming, etc.) outlined in this document. Exceptions are allowed in isolated, backend-specific parts of the code that do not interface directly with the `ggml` interfaces.
173 _(NOTE: for legacy reasons, existing code is not required to follow this guideline)_
174
175# Documentation
176
177- Documentation is a community effort
178- When you need to look into the source code to figure out how to use an API consider adding a short summary to the header file for future reference
179- When you notice incorrect or outdated documentation, please update it
180
181# Resources
182
183The Github issues, PRs and discussions contain a lot of information that can be useful to get familiar with the codebase. For convenience, some of the more important information is referenced from Github projects:
184
185https://github.com/ggml-org/llama.cpp/projects